목표
1
잼라이브 문제를 자동으로 웹브라우저에 검색하도록 하기
jamlive라고 하는 모바일 문제 풀이 방송이 있습니다.
사람들이 동시에 모바일로 접속해서 총 12개의 문제를 푸는데요, 다 맞춘 사람들은 정해진 상금을 나눠가지는 그런 게임 비슷한 것입니다. 문제는 삼지선다형으로, 출제 분야가 너무 다양해 문제의 난이도가 어려워도 문제의 글자수나 보기는 간단합니다. 그래서 혹시 문제가 나옴과 동시에 OCR로 글씨를 인식시키고, 그것을 구글이나 네이버에 검색을 하게 만든 후 보면서 문제를 풀면 더 잘 맞출수 있지 않을까 해서 시작하게 되었으나 실패했습니다. 실패한 이유는..
실패한 사진
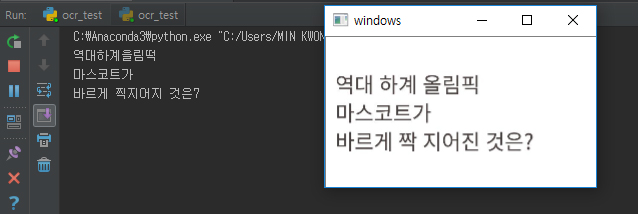
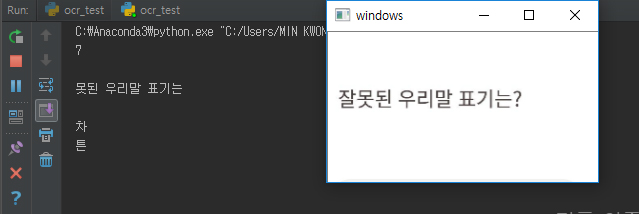
OCR이 제대로 안 되어서 그 다음단계로 진행을 못 했습니다.
과정
아이디어
1
2
3
1. 휴대폰 화면을 컴퓨터에 미러링 시켜서, 컴퓨터 모니터로 잼라이브 문제를 볼 수 있도록 한다
2. 문제가 나오면 파이썬으로 OCR을 돌려서 문제를 텍스트로 인식 후 검색엔진에 검색하게 한다
3. 나는 그 검색 결과를 참고로 해서 문제를 푼다
-
첫번째는 모비젠이라는 프로그램으로 했습니다. 휴대폰 화면을 컴퓨터에 띄울 수 있으며, 클릭 등의 조작도 컴퓨터로 가능합니다. 모비젠 홈페이지 휴대폰 화면의 띄워진 창을 자동으로 파이썬이 인식하면 좋을텐데, 어떻게 하는지 몰라서 휴대폰 화면의 위치를 특정한 곳으로 고정해놓고 진행했습니다.
-
두번째는 pytesseract를 사용했습니다. 여기서 실패했는데요, 다른 게 더 좋은 게 있는지 잘 모르겠고, 제가 뭔가 실수한 게 있을 거라는 생각도 듭니다.
-
세번째는 시작도 못 하고 중단된 상태입니다.
코드 설명
일단 화면을 다루어야하므로 OpenCV와 ImageGrab을 import 했습니다.
1
2
3
4
5
6
import cv2
from PIL import ImageGrab
import numpy as np
screen = ImageGrab.grab(bbox=(180, 250, 450, 400)) # 모니터의 해당 좌표를 캡쳐
cv2.imshow('windows',np.array(screen)) # 위의 화면을 창으로 띄움
휴대폰 화면의 문제가 나오는 부분이 컴퓨터 모니터에서 (180, 250, 450, 400)이 되도록 창을 위치시켜놓고 진행했습니다. 위의 스크린샷에서 문제를 캡쳐해서 windows 창에 띄우는 과정이 바로 이 코드입니다.
그 다음에는 위의 화면을 pytesseract로 OCR을 하는 것인데요. 코드는 아래와 같습니다.
1
2
3
4
import pytesseract
text = pytesseract.image_to_string(screen, lang='kor') # `screen`를 한국어 OCR을 돌림
print(text) # 그리고 그것을 프린트
이까지만 하면 이제 핵심 기능은 잘 작동합니다. 제가 바랐던 것은 특정 버튼을 누르면 그 즉시 OCR을 돌리는 것이었는데요, 그래서 화면을 캡처하는 것을 while 루프에 넣고 키보드의 ‘a’ 버튼을 누르면 OCR이 돌아가도록 했습니다. q를 누르면 창이 꺼지구요.
아래 전체 코드를 보시면 이해가 될 것입니다.
전체 소스코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import cv2
import time
from PIL import ImageGrab
import numpy as np
import pytesseract
while True :
screen = ImageGrab.grab(bbox=(180, 250, 450, 400)) # 화면 캡처
cv2.imshow('windows',np.array(screen)) # 캡쳐 화면 표시
time.sleep(0.5) # 0.5초마다 화면 갱신
if cv2.waitKey(33) == ord('a'): # 키보드의 a를 누르면
text = pytesseract.image_to_string(screen, lang='kor') # OCR 실행
print(text) # 결과 표시
if cv2.waitKey(25) & 0xFF == ord('q'): # 키보드의 q를 누르면
cv2.destroyAllWindows() # 창을 닫는다
break # 루프에서 나감
후기
브라우저로 자동으로 검색하게 하는 방법을 모릅니다. 작업의 특성상 새로운 브라우저를 띄우는 게 아니라 이미 켜 놓은 브라우저에서 검색어를 입력하고 검색을 실행하도록 하고 싶은데요. 비록 OCR은 실패했지만 그 다음 단계는 계속 진행을 하고 싶습니다. 나중에 시도해보고 업데이트하도록 하겠습니다. 긴 글 읽어주셔서 감사합니다.